

News|Articles|June 11, 2025
GPT-4 AI Model Outperforms Traditional Tools in Predicting Cutaneous Squamous Cell Carcinoma Outcomes
Author(s)Briana Contreras
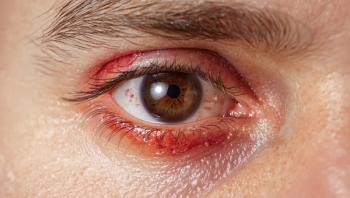
Cutaneous squamous cell carcinoma (cSCC) is the second most common form of skin cancer. While most cases are treatable, a small number can become serious and spread, leading to worse outcomes.
Advertisement
A risk prediction
CSCC is the second most common form of skin cancer. While most cases are treatable, a small number can become serious and spread, leading to worse outcomes.
Accurately identifying which tumors are more dangerous is important for deciding how to treat patients, the report shared.
Existing tools or models, such as the AJCC8 and BWH staging systems, group tumors by certain traits, but they tend to miss important risk factors and can group very different tumors together, making it harder to predict who might do poorly.
Many factors increase the risk of developing cSCC, including immunosuppression, chronic wounds, fair skin, male gender, older age, certain genetic conditions, ultraviolet (UV) radiation exposure and a history of prior squamous cell
In 2012, the estimated incidence was 140 cases per 100,000 American men and 50 per 100,000 women.
To address these limitations, researchers searched PubMed, Embase and the Cochrane Library for studies from 1999 through the end of 2023.
After applying strict criteria, 10 studies that linked risk factors to serious outcomes such as recurrence, spread or death were selected.
These studies were used to inform a large AI model, GPT-4, called AIRIS through a process called retrieval-augmented generation (RAG).
The AI created a new scoring system to predict which cSCC tumors are more dangerous.
AIRIS was tested using tumor data from NYU Langone Health and Mayo Clinic.
The dataset included 2,379 biopsy-proven cSCC cases with full clinical information.
The AI model’s predictions were compared to AJCC8 and BWH systems using statistical tests.
Researchers measured how well AIRIS could predict poor outcomes using standard metrics like sensitivity, specificity and AUC. AIRIS was also tested for consistency and ability to separate high- and low-risk cases.
It was found that AIRIS outperformed BWH and AJCC8 in a number of key areas for predicting poor outcomes in patients with cSCC.
In low-risk groups, AIRIS showed fewer poor outcomes: 50.9% for local recurrence (LR), 26.3% for nodal metastasis (NM), 17.5% for distant metastasis (DM) and 27.8% for disease-specific death (DSD).
In comparison, BWH and AJCC8 systems had nearly twice as many poor outcomes in their low-risk groups, indicating there were less consistent results.
AIRIS also showed further progression, overall.
For high-risk AIRIS classes, the poor outcome rates increased significantly: LR (49.1%), NM (73.7%), DM (82.5%) and DSD (72.2%).
As far as diagnostic performance, AIRIS had higher sensitivity for all outcomes—ranging from 49.1% to 82.5%—but slightly lower compared to BWH and AJCC8.
Although overall accuracy was lower, AIRIS demonstrated stronger predictive power, with AUC values of 0.69 (LR), 0.81 (NM), 0.85 (DM), and 0.80 (DSD)—all higher than the traditional systems.
While much data was collected, the study did have several strengths.
For example, reviewed over 2,000 primary tumors to validate AIRIS. AIRIS included important patient risk factors such as immunosuppression, lymphovascular invasion and in-transit metastasis, which are often missing from traditional staging systems, authors of the study noted.
This helped AIRIS better predict poor outcomes and showed improved sensitivity and risk discrimination compared to current standards.
However, limitations include the relatively low event rate of poor outcomes in cSCC which cab make validation challenging.
In addition, large language models such as GPT rely on probable predictions and can have biases based on their training data and inputs.
While RAG helps ground the model in reliable literature, AI-generated outputs still require careful validation, authors suggest.
Future improvements are recommended to include weighting immunosuppression categories and integrating multimodal data including imaging or gene profiles to personalize risk predictions further.
Advertisement
Related Content
Advertisement























Advertisement
Advertisement
Trending on Managed Healthcare Executive
1
1,700 sites closed, 77,000 fewer children received PEPFAR-supported treatment after PEPFAR disruption | IAS 2026
2
Renee Heffron, Ph.D., M.P.H., on choice in HIV prevention | IAS 2026
3
Renee Heffron, Ph.D., M.P.H., on the case for MK-8527 | IAS 2026
4
Zabopegdutide shows 62.5% MASH resolution rate at 48 weeks
5